アプリが4本になったので、バグ報告を1箇所に集めてAIに並列で潰させた話

ユーザーがいるアプリが4本になって、バグ報告を1箇所に集めた。集めて初めて分かったのは、報告の重大度が4本でバラバラの基準で付いていたことだ。基準を揃えて1画面に並べたら、複数のClaudeに渡して報告済みのバグを1日で潰せるようになった。商用アプリを複数持つと運営の手間がここに集中する、という話を書く。
俺が今ユーザーを抱えているアプリは4本ある。音声をリアルタイム翻訳するLiveTR、画面をそのまま日本語にするOLTranslator、英語リスニングのKikoeru、そして自分のサーバーで動く、ギルドのオークションを管理するDiscordボット AuctionBOT。アプリが増えるほど、開発よりも「ちゃんと動いているか」が気になる。実ユーザーがいるからだ。
観測できるアプリと、できないアプリ
4本のうち、自分で動きを追えるのは1本だけだ。AuctionBOTは自分のサーバーで動くDiscordボットなので、何が起きているかをそれなりに自分で調べられる。残りの3本(OLTranslator・LiveTR・Kikoeru)はユーザーの端末・環境で動く。手元に同じ環境は無いし、1つの環境では再現できないバグもある。
だから全アプリに「品質向上のため情報を送信します」という、よくあるあの導線を入れた。ユーザーの立場のときは何となくOKを押していたものだ。開発側になって、これが役に立つと分かった。バグの多くは自分で見つけるものではなく、ユーザーの環境から上がってくる。自分で観測できない分は、ユーザーからの報告で補う。
報告がアプリごとに別の場所にある
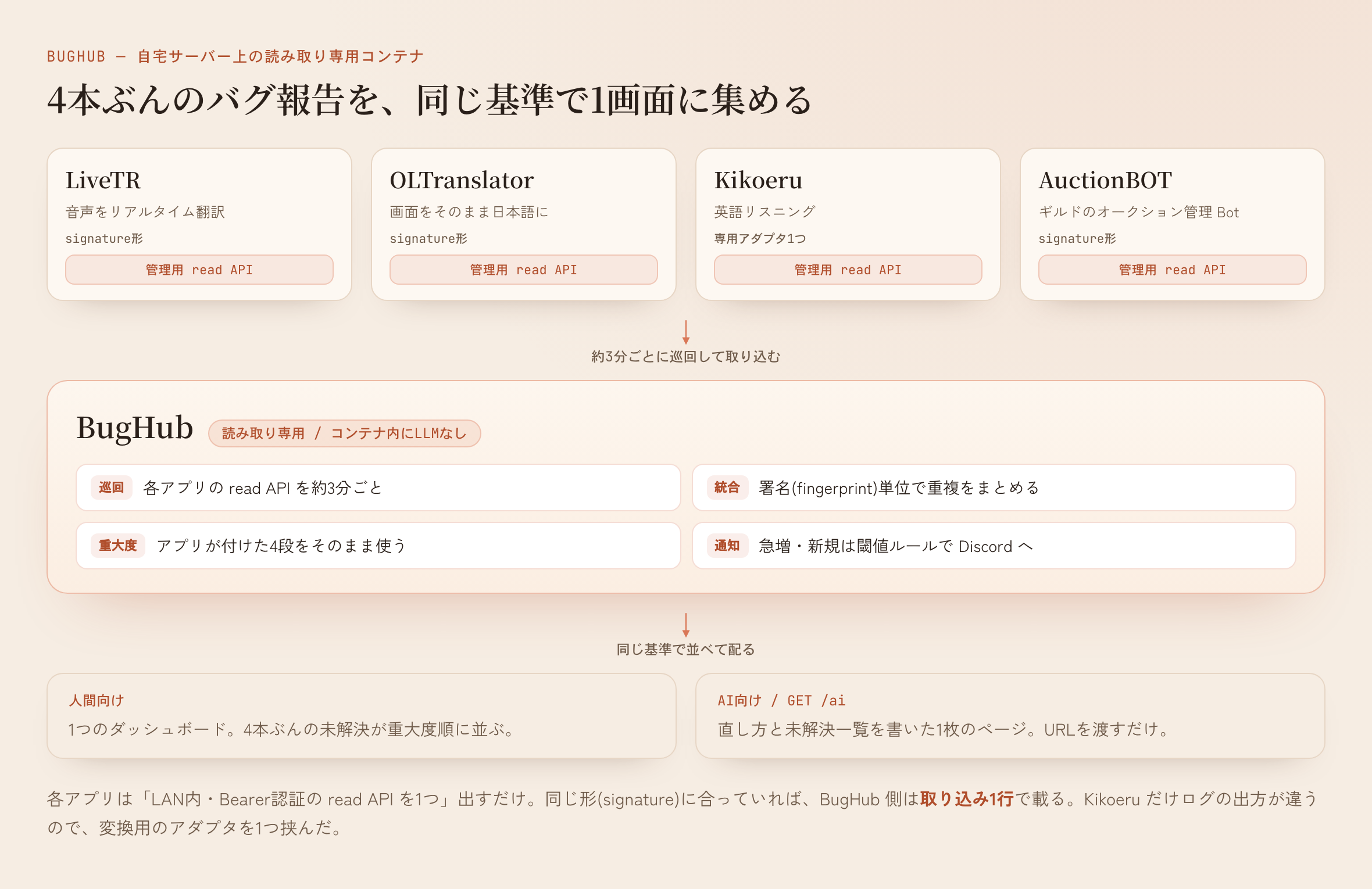
報告の仕組みを全アプリに入れたが、今度はその報告がアプリごとに別の場所に溜まった。1人+AIで4本を回していると、どのアプリが何件抱えているかを横並びで見られない。直す前に、今どのアプリに問題が出ているかを確認する場所が無かった。
そこで集約システムを作った。自宅サーバー上で動く読み取り専用の内部コンテナで、BugHubと名付けた。やることは単純で、各アプリがLAN内に出している管理用の読み取りAPIを約3分ごとに巡回し、全部を1つのダッシュボードに並べる。アプリ側は「LAN内・Bearer認証の読み取りAPIを1つ」出すだけ。バグを署名(fingerprint)単位でまとめて返す。署名は「どのモジュールの、どの種類の、どんなメッセージ雛形か」のハッシュで、可変値は含まないから、同じ原因のバグは同じ値になる。各バグには重大度・メッセージ雛形(可変値や個人情報はマスク済み)・累計発生数・最終発生時刻・状態(未解決か解決済みか)が付く。
BugHub側は、この形(signature形と呼んでいる)に合っていれば取り込みは1行だ。
// この形を出すアプリは、ソース一覧に1行足すだけで載る
const SOURCES = [
{ name: "AuctionBOT", api: AUCTION_API },
{ name: "OLTranslator", api: OLTR_API },
{ name: "LiveTR", api: LIVETR_API },
// Kikoeru だけログ形式が違うので、小さなアダプタを1つ挟んだ
{ name: "Kikoeru", api: KIKOERU_API, adapt: kikoeruAdapter },
];
LiveTR・OLTranslator・AuctionBOTは最初から同じ形に揃えた。Kikoeruだけログの出方が違ったので、変換用の小さなアダプタを1つ挟んだ。これで4本が横に並んだ。
基準がバラバラだと、並べて分かった
並べてみて気づいたのは、報告の重大度がアプリごとに別々の基準で付いていたことだ。あるアプリの「重大」が、別のアプリでは「警告」相当だったりする。同じ基準で並べて初めて、上から順に対処していい一覧になる。
なので重大度のラベルを4段に統一した。アプリが付けて、BugHubは再判定せずそのまま使う。
| ラベル | 意味 |
|---|---|
| 致命(fatal) | アプリが止まる/動かない。最も深刻。 |
| 重大(high) | 動いてはいるがユーザーに実害が出る(誤動作・データ欠落など)。致命の一歩手前。 |
| 警告(warn) | 理想的な状態ではないが動いている。直すべき。 |
| 情報(info) | 直すべきだが今は解決方法が無いもの、もしくは記録だけ残す参考情報。 |
定義は4行だが、実装は各アプリの報告の仕組みそのものに関わる。どのイベントをどの段に割り当てるかを4本それぞれで見直すことになった。結果として、各アプリで「バグを直しつつ、報告機構も作り直す」改修になった。
共通仕様を、AIにどう渡すか
ラベルを統一すると、次は「この共通仕様を直す側にどう渡すか」になる。直すのは俺ではなくAIだ。プロジェクトごとに別のVSCode・別のClaudeが立つので、毎回口頭で仕様を説明していたら統一した意味が無い。
これも1枚のページにした。GET /ai を叩くと、AI向けに書かれた1枚のMarkdownが返る。中身の柱はこうだ。
- 重大度4段の基準(上のもの)
- 直す手順: ①未解決を取得 → ②該当アプリのプロジェクトを直す → ③本番にデプロイして再発しないか確認 → ④確認できたらアプリ側へ解決を記録。先に解決記録を打たない。自信が無いものは触らない。
- この時点での未解決一覧(各項目に解決コマンド付き)
加えて、アプリ別の「解決をどこに打つか」のテーブルと、「新しいアプリを連携するには」の共通仕様も同じページに載せてある。
AIに直させてデプロイまで任せる仕組み自体は前に書いた。今回その上に足したのは、複数アプリの報告を同じ基準で集約して、1本のURLで渡せるようにした部分だ。別のアプリに対して「これをBugHubに集約できるようにして」と言えば、AIはこのページの共通仕様に従ってアプリ側のAPIを実装する。新しいアプリの統合も、同じ1本のURLを渡すだけで済む。
解決はBugHubではなくアプリ側に記録する。アプリ側が正で、BugHubはその状態をコピーして表示しているだけだ。BugHub側で消しても次の巡回でアプリ側の状態に上書きされて戻るし、アプリ側で再発を検知すれば自動で「未解決」に戻る。
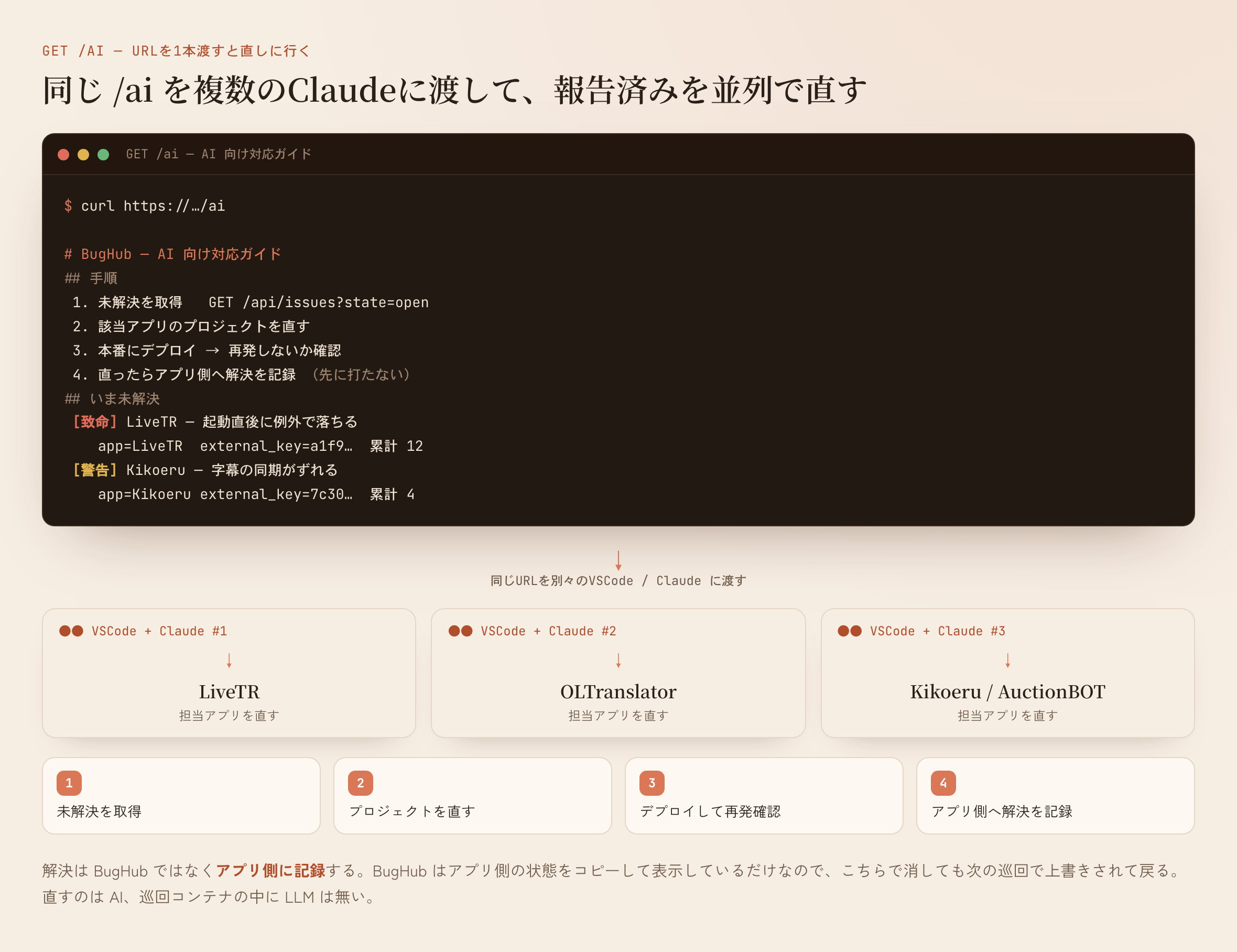
複数のClaudeに渡して、1日で片付けた
ここまで揃えてから、報告済みのバグを片付けにかかった。複数のVSCodeにそれぞれClaudeを立てて、全部に /ai のURLを渡し、「これを見て直して」と指示した。同じ一覧を同じ基準で見ているので、どのClaudeも未解決を取って、自分の担当アプリを直して、デプロイして、検証して、解決を打つ。これを並列で回して、その1日でひととおり片付いた。
巡回コンテナの中にLLMは無い。約3分ごとの巡回も、急増や新規の即時アラートも、純粋な閾値ルールで動く。AIが関わるのは外側だけで、バグを直す側と、週1のCodexまとめだ。
今いちばん手がかかるのはここ
個人で商用アプリを複数持つと、運営の手間がここに集中する。新機能を足す時間より、上がってきた報告を捌く時間のほうが増える。作る速さの話は前に書いたが、その続きとして、動かし続ける側にも同じ整理が要る。それが今の状況だ。
今は、4本ぶんの未解決が同じ基準で1画面に並んでいて、URLを1本渡せばAIがそこから直しに行く。ユーザーのときに何となくOKを押していた「品質向上のため情報を送信します」は、開発側ではこういう使われ方をしていた。